

Якщо ви хоч трохи цікавилися питанням внутрішньої оптимізації сайтів, то, напевно, зустрічали термін robots txt. Саме йому і присвячена наша сьогоднішня тема.
Зараз ви дізнаєтеся, що таке robots txt, як він створюється, яким чином веб-майстер задає в ньому потрібні правила, як обробляється файл robots.txt пошуковими роботами і чому відсутність цього файлу в корені веб-ресурсу - одна з найсерйозніших помилок внутрішньої оптимізації сайту. Буде цікаво!

Що таке robots.txt
Технічно robots txt - це звичайний текстовий документ, який лежить в корені сайту і інформує пошукових роботів про те, які сторінки та файли вони повинні сканувати та індексувати, а для яких накладено заборону. Але це найпримітивніший опис. Насправді з robots txt все трохи складніше.
Файл robots txt це як «адміністратор готелю». Ви приходите в неї, адміністратор видає вам ключі від номера, а також каже, де ресторан, SPA, зона відпочинку, кабінет управителя та інше. А ось в інші номери та приміщення для персоналу вхід вам замовлено. Точно так само і з robots txt. Тільки замість адміністратора – файл, замість клієнта – пошукові роботи, а замість приміщень – окремі веб-сторінки та файли. Порівняння грубе, але доступне і зрозуміле.
Для чого потрібний файл robots.txt
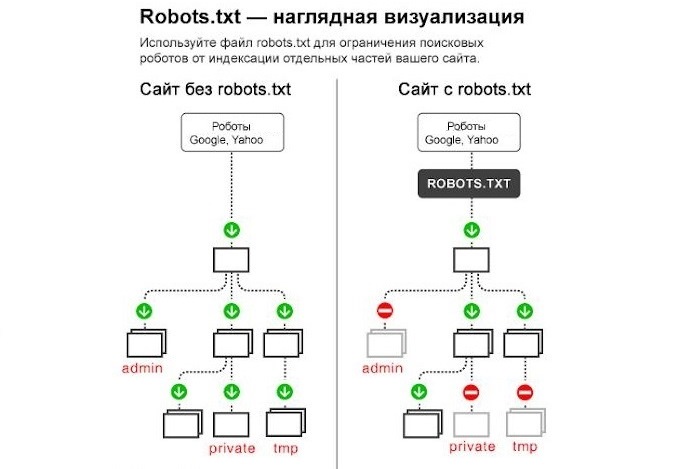
Без цього файлу пошуковики хаотично блукають сайтом, скануватимуть та індексуватимуть буквально все поспіль: дублі, службові документи, сторінки з текстами «заглушками» (Lorem Ipsum) тощо.
Правильний robots txt не дає такому відбуватися і буквально веде роботів сайтом, підказуючи, що дозволено індексувати, а що необхідно пропустити.
Існують спеціальні директиви robots txt для цих завдань:
- Allow - Допускає індексацію.
- Disallow – забороняє індексацію.
Крім того, можна одразу прописати, яким конкретно роботам дозволено чи заборонено індексувати задані сторінки. Наприклад, щоб заборонити індексацію директорії /private/ пошуковим роботам «Гугл», в роботі необхідно прописати User-agent:
User-agent: Google
Disallow: /private/
Також ви можете вказати основне дзеркало веб-сайту, встановити шлях до Sitemap, позначити додаткові правила обходу через директиви та інше. Можливості robots txt досить великі.
І ось ми розібралися, навіщо потрібний robots txt. Далі складніше - створення файлу, його наповнення та розміщення на сайті.
Як створити файл robots.txt для веб-сайту?
Отже, як створити файл robots txt?
Створити та змінювати файл найпростіше у програмі «Блокнот» або іншому текстовому редакторі, що підтримує формат .txt. Спеціальне програмне забезпечення для роботи з robots txt не знадобиться.
Створіть звичайний текстовий документ із розширенням .txt і помістіть його в корінь веб-ресурсу. Для розміщення підійде будь-який FTP-клієнт. Після розміщення обов'язково варто перевірити robots txt - чи знаходиться файл за потрібною адресою. Для цього у пошуковому рядку браузера потрібно прописати адресу:
ім'я_сайту/robots.txt
Якщо все зроблено правильно, ви побачите у вкладці дані robots txt. Але без команд і правил він, звісно, не працюватиме. Тому переходимо до більш складного наповнення.
Символи у robots.txt
Крім згаданих вище функцій Allow/Disallow, robots txt прописуються спецсимволи:
- "/" - вказує, що ми закриваємо файл або сторінку від виявлення роботами "Гугл" і т. д.;
- "*" - прописується після кожного правила і позначає послідовність символів;

- "$" - обмежує дію "*";

- "#" - дозволяє закоментувати будь-який текст, який веб-майстер залишає собі або іншим фахівцям (своєї нотатки, нагадування, інструкція). Пошуковики не зчитують закоментований текст.
Синтаксис у robots.txt
Описані у файлі robots.txt правила - це його синтаксис та різного роду директиви. Їх досить багато, ми розглянемо найбільш значущі — ті, які ви, швидше за все, використатимете.
User-agent
Це директива, яка вказує, для яких пошукових роботів будуть діяти такі правила. Прописується так:
User-agent: * ім'я пошукового робота
Приклади роботи: Googlebot та інші.
Allow
Це роздільна здатність директиви для robots txt. Допустимо, ви прописуєте такі правила:
User-agent: * ім'я пошукового робота
Allow: /site
Disallow: /
Так у robots txt ви забороняєте роботу аналізувати та індексувати весь веб-ресурс, але заборона не стосується папки site.
Disallow
Це протилежна директива, яка закриває від індексації лише прописані сторінки чи файли. Щоб заборонити індексувати певну папку, потрібно прописати:
Disallow: /folder/
Також можна заборонити сканувати та індексувати всі файли вибраного розширення. Наприклад:
Disallow: /*.css$
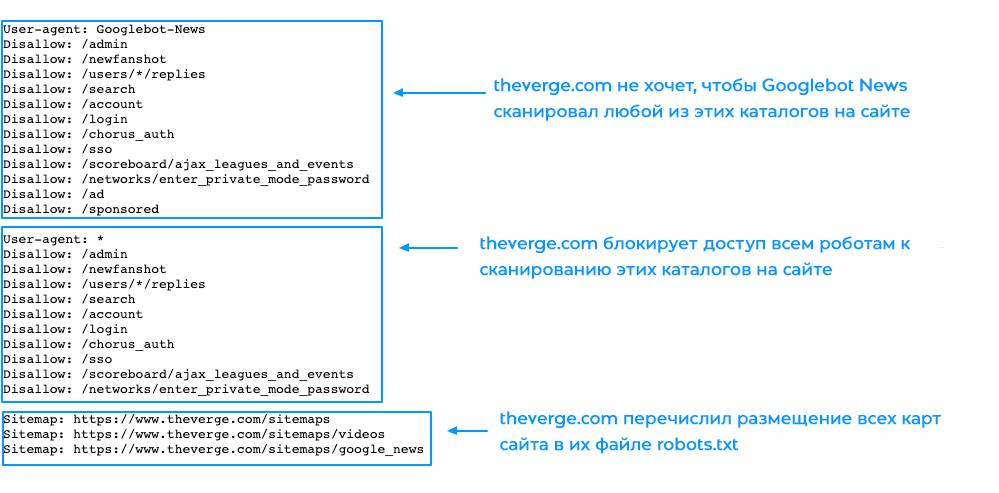
Sitemap
Ця директива robots txt направляє пошукових роботів до опису структури вашого ресурсу. Це важливо для SEO. Ось приклад:
User-agent: *
Disallow: /site/
Allow: /
Sitemap: http://site.com/sitemap1.xml
Sitemap: http://site.com/sitemap2.xml
Crawl-delay
Директива обмежує частоту аналізу сайту і знижує навантаження на сервер. Тут прописується час у сік. (третій рядок):
User-agent: *
Disallow: /site
Crawl-delay: 4
Clean-param
Забороняє індексацію сторінок, сформованих із динамічними параметрами. Суть у тому, що пошукові системи сприймають їх як дублі, а це погано для SEO. Про те, як знайти дублі сторінок на сайті , ми вже розповідали. Вам потрібно прописувати директиву:
Clean-param: p1[&p2&p3&p4&..&pn] [Шлях до динамічних сторінок]
Приклади Clean-param у robots txt:
Clean-param: kol_from1&price_to2&pcolor /polo.html # тільки для polo.html
або
Clean-param: kol_from1&price_to2&pcolor / # для всіх сторінок сайту
До речі, радимо прочитати нашу статтю " Як просто перевірити індексацію сайту " - в ній багато корисного на цю тему. Плюс є інформативна стаття " Сканування сайту в Screaming Frog ". Рекомендуємо ознайомитись!
Особливості налаштування robots.txt для «Гугла»
Насправді синтаксис файла robots.txt цих систем відрізняється незначно. Але є кілька моментів, які ми радимо враховувати.
Google не рекомендує приховувати файли із CSS-стилями та JS-скриптами від сканування. Тобто правило має виглядати так:
User-agent: Googlebot
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Allow: *.css
Allow: *.js
Host: www.site.com
Приклади налаштування файлу robots.txt
Кожна CMS має свою специфіку налаштування robots txt для сканування та індексації. І найкращий спосіб зрозуміти різницю – розглянути кожен приклад robots txt для різних систем. Так і вчинимо!
Приклад robots txt для WordPress
Роботс для WordPress у класичному варіанті виглядає так:
User-agent: Googlebot
Disallow: /cgi-bin # службова папка для зберігання серверних скриптів
Disallow: /? # всі параметри запиту на головній
Disallow: /wp- # файли WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результати пошуку
Disallow: /search # результати пошуку
Disallow: */page/ # сторінки пагінації
Disallow: /*print= # сторінки для друку
Allow: *.css # відкрити всі файли стилів
Allow: *.js # відкрити все з js-скриптами
User-agent: *
Disallow: /cgi-bin # службова папка для зберігання серверних скриптів
Disallow: /? # всі параметри запиту на головній
Disallow: /wp- # файли WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результати пошуку
Disallow: /search # результати пошуку
Disallow: */page/ # сторінки пагінації
Disallow: /*print= # сторінки для друку
Sitemap:http://site.ua/sitemap.xml
Sitemap: http://site.ua/sitemap1.xml
Приклад robots.txt для "Бітрікс"
Одна з головних проблем «Бітрікс» — по дефолту пошукові системи зчитують та проводять індексацію службових сторінок та дублів. Але це можна запобігти, правильно прописавши robots txt:
User-Agent: Googlebot
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/tools/conversion/ajax_counter.php
Allow: /bitrix/components/main/
Allow: /bitrix/css/
Allow: /bitrix/templates/comfer/img/logo.png
Allow: /personal/cart/
Sitemap: https://site.ua/sitemap.xml
Приклад robots.txt для OpenCart
Розглянемо приклад robots txt для платформи електронної комерції OpenCart:
User-agent: Googlebot
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Sitemap: http://site.ua/sitemap.xml
Приклад robots.txt для Joomla
У «Джумлі» роботс виглядає так:
User-agent: Googlebot
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Sitemap: http://www.site.ua/sitemap.xml
Приклад robots.txt для Drupal
Для Drupal:
User-agent: *
Disallow: /database/
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /sites/
Disallow: /themes/
Disallow: /scripts/
Disallow: /updates/
Disallow: /profiles/
Disallow: /profile
Disallow: /profile/*
Disallow: /xmlrpc.php
Disallow: /cron.php
Disallow: /update.php
Disallow: /install.php
Disallow: /index.php
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /contact/
Disallow: /logout/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: *register*
Disallow: *login*
Disallow: /top-rated-
Disallow: /messages/
Disallow: /book/export/
Disallow: /user2userpoints/
Disallow: /myuserpoints/
Disallow: /tagadelic/
Disallow: /referral/
Disallow: /aggregator/
Disallow: /files/pin/
Disallow: /your-votes
Disallow: /comments/recent
Disallow: /*/edit/
Disallow: /*/delete/
Disallow: /*/export/html/
Disallow: /taxonomy/term/*/0$
Disallow: /*/edit$
Disallow: /*/outline$
Disallow: /*/revisions$
Disallow: /*/contact$
Disallow: /*downloadpipe
Disallow: /node$
Disallow: /node/*/track$
Disallow: /*&
Disallow: /*%
Disallow: /*?page=0
Disallow: /*section
Disallow: /*order
Disallow: /*?sort*
Disallow: /*&sort*
Disallow: /*votesupdown
Disallow: /*calendar
Disallow: /*index.php
Allow: /*?page=
Disallow: /*?
Sitemap: http://шлях до вашої карти XML формату
Висновки
Файл robots txt – функціональний інструмент, завдяки якому веб-розробник дає інструкції пошуковим системам, як взаємодіяти з сайтом. Завдяки йому ми забезпечуємо правильну індексацію, захищаємо веб-ресурс від потрапляння під фільтри пошукових систем, знижуємо навантаження на сервер та покращуємо параметри сайту для SEO.
Щоб правильно прописати інструкції файлу robots.txt, дуже важливо чітко розуміти, що ви робите, і навіщо ви це робите. Відповідно, якщо не впевнені, краще зверніться за допомогою до фахівців. У нашій компанії налаштування robots txt входить до послуги внутрішньої оптимізації сайту для пошукових систем .
FAQ
Що таке файл robots.txt?
Robots txt - це документ, що містить правила індексації вашого сайту, окремих його файлів або URL-пошуковиками. Правила, описані у файлі robots.txt, називають директивами.
Навіщо потрібний файл robots.txt?
Robots txt допомагає закрити від індексації окремі файли, дублі сторінок, документи, що не несуть користі для відвідувачів, а також сторінки, що містять неунікальний контент.
Де знаходиться файл robots.txt?
Він розміщується у кореневій папці веб-ресурсу. Щоб перевірити його наявність, достатньо до URL-адреси вашого веб-ресурсу дописати /robots.txt і натиснути Enter. Якщо вона на місці, відкриється його сторінка. Так можна переглянути файл на будь-якому сайті, навіть на сторонньому. Просто додайте адресу /robots.txt.





